Here are my slides:
Or if you like PDF:
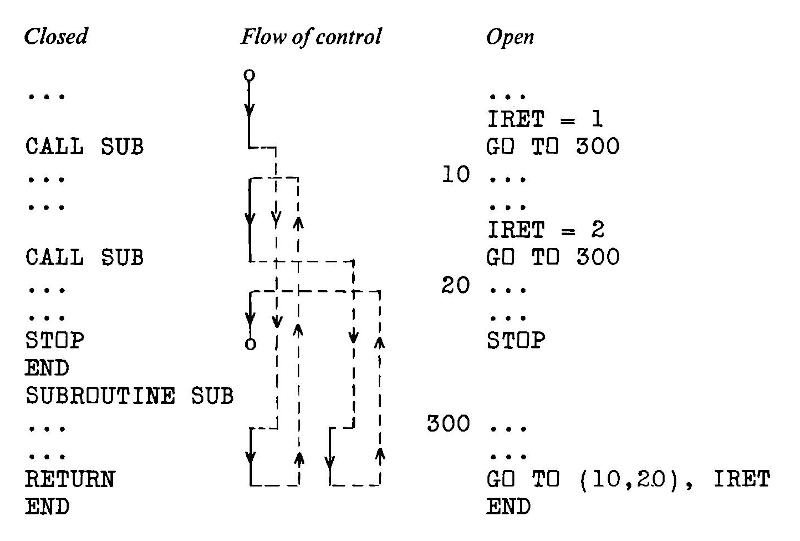
Imagine you have a programming task that involves parsing and analyzing text. Nothing complicated: maybe just breaking it into tokens. Now imagine the only programming language you had available:
Sounds impossible, right? But that’s the world described in Colin Day’s book from 1972, Fortran techniques with special reference to non-numerical applications.
The programming language used is USA Standard FORTRAN X3.9 1966, commonly known as Fortran IV after IBM’s naming convention. For all it looks crude today, Fortran was an efficient, sod-the-theory-just-get-the-job-done language that allowed numerical problems to be described as a text program and solved with previously impossible speed. Every computer shipped with some form of Fortran compiler at the time. Day wasn’t alone working within Fortran IV’s text limitations in the early 1970s: the first Unix tools at Bell Labs were written in Fortran IV — that was before they built themselves their own toolchain and invented the segmentation fault.
The book is a small (~ 90 page) delight, and is a window into system limitations we might almost find unimaginable. Wanna create a lookup table of a thousand entries? Today it’s a fraction of a thought and microseconds of program time. But nearly fifty years ago, Colin Day described methods of manually creating two small index and target arrays and rolling your own hash functions to store and retrieve stuff. Text? Hollerith constants, mate; that’s yer lot — 6HOH HAI might fit in one computer word if you were running on big iron. Sorting and searching (especially without recursion) are revealed to be the immensely complex subjects they are, all hidden behind today’s one-liner methods. Day shows methods to simulate recursion with arrays standing in for pointer stacks of GO TO targets (:coding_horror_face:). And if it’s graphics you want, that’s what the line printer’s for:

Why do I like this book enough to track down a used copy, import it, scan it, correct it and upload it to the Internet Archive? To me, it shows the layers we now take for granted, and the privilege we have with these hard problems of half a century ago being trivially soluble on a $10 computer the size of a stick of gum. When we run today’s massive AI models with little interest in the underlying assumptions but a sharp focus on getting the results we want, we do a disservice to the years of R&D that got us here.
The ‘charges for computing time’ comment above is from Colin’s website. Early central computing facilities had the SaaS billing down solid, partly because many mainframes were rented from the vendor and system usage was accounted for in minute detail. Apparently the system Colin used (when a new lecturer) was at another college, and it was the custom to send periodic invoices for CPU time and storage used back to the user’s department. Nowhere on these invoices did it say that these accounts were for information only and were not payable. Not the best way to greet your users.
(Incidentally, if you hate yourself and everyone else around you, you can get a feel of system billing on any Linux system by enabling user quotas. You’ll very likely stop doing this almost immediately as the restrictions and reporting burden seem utterly alien to us today.)
While the book is still very much in copyright, the copy I have sat unread at Lakehead University Library since June 1995; the due date slip’s still pasted in the back. It’s been out of print at Cambridge University Press since May 1987, even if they do have a plaintive/passive aggressive “hey we could totally make an ebook of this if you really want it†link on their site. I — and the lovely folks hosting it at the Internet Archive — have saved them from what’s evidently too much trouble. I won’t even raise an eyebrow if they pull a Nintendo and start selling this scan.
Colossal thanks to Internet Archive for making the book uploading process much easier than I thought it was. They’ve completely revamped the processing behind it, and the fully open-source engine gives great results. As ever, if you assumed you knew how to do it, think again and read the How to upload scanned images to make a book guide. Uploading a zip file of images is much easier than mucking about with weird command-line TIFF and PDF tools. The resulting PDF is about half the size of the optimized scans I uploaded, and it’s nicely tagged with metadata and contains (mostly) searchable text. It took more than an hour to process on the archive’s spectacularly powerful servers, though, so I hate to think what Colin Day’s bill would have been in 1972 for that many CPU cycles … or if even a computer of that time, given enough storage, could complete the project by now.
Almost any part of suburban Toronto brings a sameness of houses. Many neighbourhoods were built as a block, in the same year, in the same style. In order to encourage solid and financially-sound building design, the government agency Canada Mortgage and Housing Corporation (initially Central Mortgage and Housing Corporation; but always CMHC) sponsored house design competitions and paid architects a royalty for use of their designs in return for making the plans available inexpensively to all.
(I should note that that “available … to all” came with a fairly heavy dose of colonialism. As with credit to Francophone Canadians in the 19th century, mortgage finance was denied to First Nations people in Canada until very recently. Just part of the conciliation we have to do before there’s a hope of useful reconciliation.)
So many suburban neighbourhoods come straight out of the CMHC catalogues. CMHC houses are featured in Douglas Coupland’s Souvenir of Canada. They’re not part of the the whole majestic Canada thing, but they are as Canadian as _____.
I came across a tweet the other day about the CMHC catalogues:
I went to the site and there were loads of catalogues there, all languishing unbrowsably in boring old FTP folders. So I decided to upload all the CMHC Small House designs that I could find on archive.org. Here’s a sampler from each of the decades that are available:


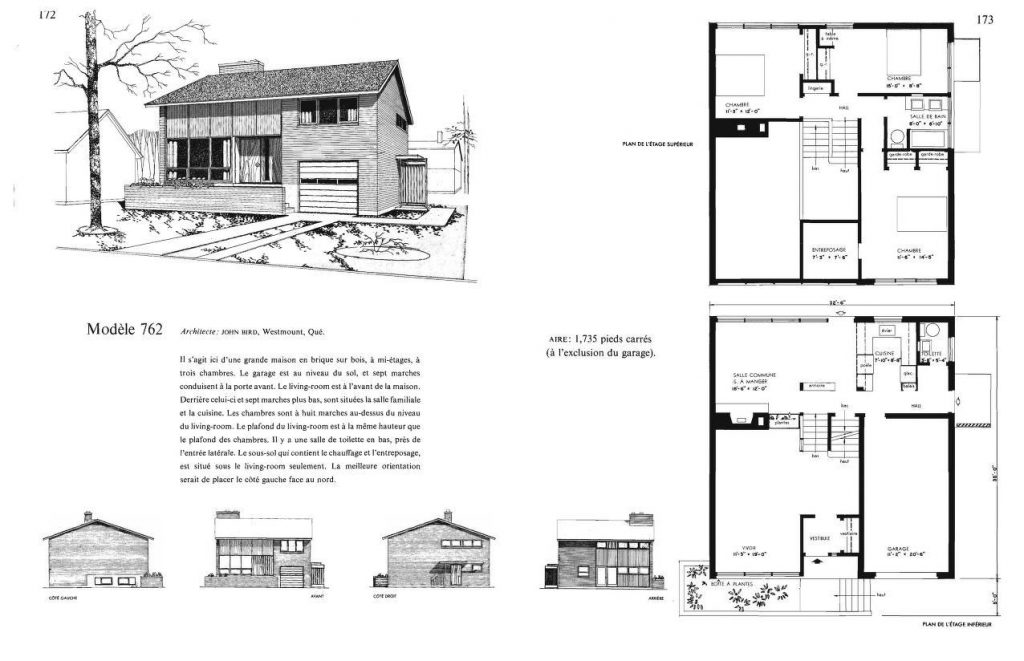
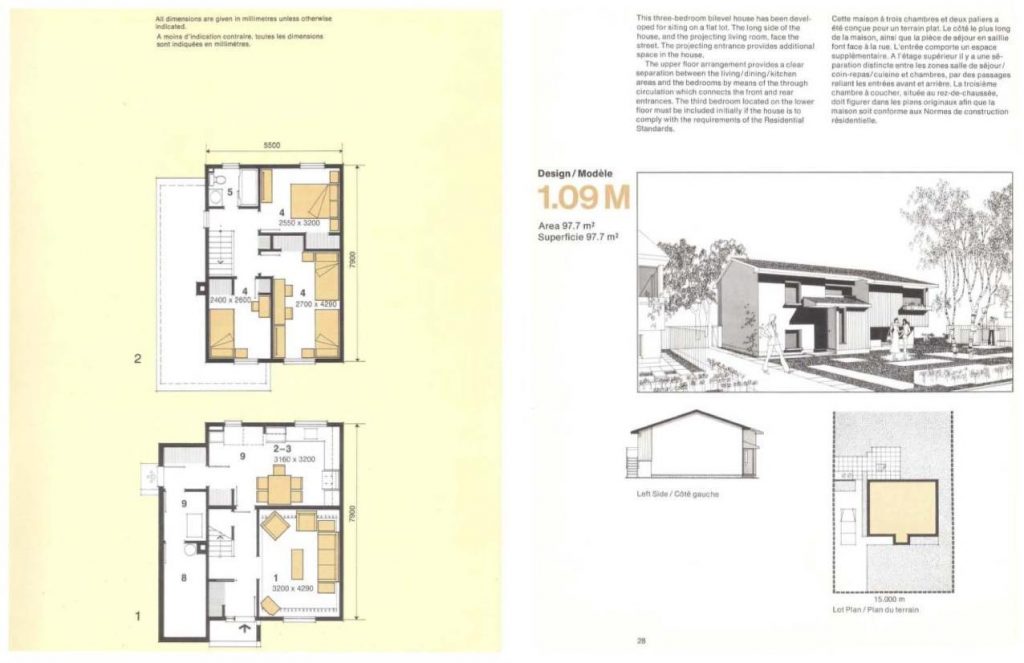
So many houses. So many neighbourhoods. So many families. So many stories. So many homes.
These are all of the CMHC design catalogues that I put up on Internet Archive:
They’re all downloaded from CMHC’s FTP site (ftp://ftp.cmhc-schl.gc.ca/chic-ccdh/HousePlans/). A dedicated urban architecture archivist could have a field day there.
CMHC link via Elie Bourget – thanks!
TL;DR Update — The disk images are here: creator:”LOGIC (“Loyal Ontario Group Interested In Computers”)”
The Apple II post from the other day wasn’t as random as it might seem. Through a friend, I got given not just the Apple IIe previously pictured, but also an Apple IIgs and the almost-complete disk library from a local Apple user group.
Logic (“Loyal Ontario Group Interested In Computers”) appears to be defunct now. The Internet Archive has 20+ years of their website logicbbs.org archived, but the domain no longer resolves. It’s a shame if they are completely gone, because user groups contain social history. Once it’s gone, well … never send to know for whom the CtrlG tolls; it tolls for thee.
I’m going to archive as much of the Logic disk library as I can. I’ve been chatting with Jason Scott, and he’s keen to see that the disk images are preserved.
I’d never used an Apple II before. They’re quite, um, different from anything else I’d used. Sometimes hideously low-level (slot numbers!), sometimes rather clever (I/O streams from any of the cards can control the computer). Since nothing but an Apple II can read Apple II disks, I’ve got the IIgs running ADTPro sending images via serial to a Linux machine. It’s pretty quick: a 140 K disk image transfers in around 25 seconds, an 800 K image in just under two minutes. I’m marshalling the images with AppleCommander and trying to keep everything intact despite having little idea what I’m doing.
(Apple II annoyance: searching for the term is harder than it needs to be, as people will try to use the typography of the time and refer to it as “Apple ][”, or “Apple //”. Even though the Unicodely-correct representation should be “Apple Ⅱ”, nobody uses it. I’m going to stick with the two-capital-eyes version ‘cos it’s easier to type.)
 Just uploaded Les éléments de l’art arabe: Le trait des entrelacs by Jules Bourgoin (aka Arabic Geometrical Pattern & Design) to archive.org. This is much cleaned up from the Google Books scan, which had many duplicate pages and no metadata.
Just uploaded Les éléments de l’art arabe: Le trait des entrelacs by Jules Bourgoin (aka Arabic Geometrical Pattern & Design) to archive.org. This is much cleaned up from the Google Books scan, which had many duplicate pages and no metadata.
This is much better than the (now returned) Kindle edition …

As I appear to have broken Catherine‘s ability to play Crystal Quest by upgrading her eMac to 10.3.9, I need to find an alternative way to run it. I remember running Basilisk II years ago on a very old Linux box — indeed, my ancient instructions are still here: archive.org :: Installing Mac OS 7.5.3 under Basilisk II on Linux, and quite amazingly, are still useful.
I found the following helpful to get it going under OS X:
The Hut Sut Song, perhaps the most infectious earworm you’ll ever hear.
… or if you want it a bit more accessible, here is an mp3 of The Hut Sut Song, converted from the same source.
Further to Matt Seaton’s article in the Guardian about atrocious cycle facilities, and highlighting Warrington Cycle Campaign’s Facility of the Month, can I just say that Pete Owens of WCC got the idea for the web page from my Crappy Lanes (archive.org copy) site?
My folks have been visiting for the last couple of weeks (we’re just about to leave for the airport), and Dad asked for some links we discussed. The following will probably make little or no sense to other readers:
{kind=link}