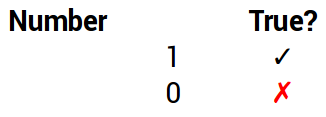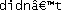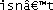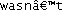this image is supposed to be made almost entirely of sextant blocks, the Unicode characters around U+1FB00 – U+1FB1E made out of two columns of three blocks. They’re originally from broadcast teletext, and were made to build low-resolution images on a text screen
Making the pixel to character map is quite tricky. The Sextant character block isn’t contiguous, and it’s not in the order we need. It’s also missing four characters: empty block, full block, left half block and right half block. These have to be pulled in from other Unicode blocks.
This is the map I came up with, from 0–63 with LSB at bottom right and MSB at top left:
I just got brian d. foy’s Learning Perl 6 from the library. It’s a pretty good book, though it’ll take a good few readings for some of Perl 6’s features to stick.
Since Perl 6 is built using Unicode from the ground up, it does two rather wonderful things when dealing with numbers:
regular expressions match numerals beyond 0–9: ٤ is as much four as 4
numeric constants can (pretty much) be expressed in terms of Unicode values in your Perl 6 source code. Assigning π to a variable does what you think it does. Dividing by ¼ is the same as multiplying by, well, ٤.
So herewith a table (probably incomplete, and very unlikely to render properly for you) of Unicode glyphs accepted by Perl 6 as numeric values:
It’s been so long since I’ve programmed in Perl. Twelve years ago, it was my life, but what with the Raspberry Pi intervening, I hadn’t used it in a while. It’s been so long, in fact, that I wasn’t aware of the new language structures available since version 5.14. Perl’s Unicode support has got a lot more robust, and I’m sick of Python’s whining about codecs when processing anything other than ASCII anyway. So I thought I’d combine re-learning some modern Perl with some childish amusement.
What I came up with was a routine to convert ASCII alphanumerics ([0-9A-Za-z]) to Unicode Enclosed Alphanumerics ([⓪-⑨Ⓐ-Ⓩⓐ-ⓩ]) for advanced lulz purposes. Ⓘ ⓣⓗⓘⓝⓚ ⓘⓣ ⓦⓞⓡⓚⓢ ⓡⓐⓣⓗⓔⓡ ⓦⓔⓛⓛ:
#!/usr/bin/perl
# annoying.pl - ⓑⓔ ⓐⓝⓝⓞⓨⓘⓝⓖ ⓦⓘⓣⓗ ⓤⓝⓘⓒⓞⓓⓔ
# created by scruss on 2014-05-18
use v5.14;
# fun UTF8 tricks from http://stackoverflow.com/questions/6162484/
use strict;
use utf8;
use warnings;
use charnames qw( :full :short );
sub annoyify;
die "usage: $0 ", annoyify('string to print like this'), "\n" if ( $#ARGV < 0 );
say annoyify( join( ' ', @ARGV ) );
exit;
# 💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩💩
sub annoyify() {
# convert ascii to chars in circles
my $str = shift;
my @out;
foreach ( split( '', $str ) ) {
my $c = ord($_); # remember, can be > 127 for UTF8
if ( $c == charnames::vianame("DIGIT ZERO") )
{
# 💩💩💩 sigh; this one's real special ... 💩💩💩
$c = charnames::vianame("CIRCLED DIGIT ZERO");
}
elsif ($c >= charnames::vianame("DIGIT ONE")
&& $c <= charnames::vianame("DIGIT NINE") )
{
# numerals, 1-9 only (grr)
$c =
charnames::vianame("CIRCLED DIGIT ONE") +
$c -
charnames::vianame("DIGIT ONE");
}
elsif ($c >= charnames::vianame("LATIN CAPITAL LETTER A")
&& $c <= charnames::vianame("LATIN CAPITAL LETTER Z") )
{
# upper case
$c =
charnames::vianame("CIRCLED LATIN CAPITAL LETTER A") +
$c -
charnames::vianame("LATIN CAPITAL LETTER A");
}
elsif ($c >= charnames::vianame("LATIN SMALL LETTER A")
&& $c <= charnames::vianame("LATIN SMALL LETTER Z") )
{
# lower case
$c =
charnames::vianame("CIRCLED LATIN SMALL LETTER A") +
$c -
charnames::vianame("LATIN SMALL LETTER A");
}
else {
# pass thru non-ascii chars
}
push @out, chr($c);
}
return join( '', @out );
}
Yes, I really did have to do that special case for ⓪; ⓪…⑨ are not contiguous like ASCII 0…9. ⓑⓞⓞ!
Years ago, I worked in multilingual dictionary publishing. I was on the computing team, so we had to support the entry and storage of text in many different languages. Computers could display accented and special characters, but we were stuck with 8-bit character sets. This meant that we could only have a little over 200 distinct characters display in the same font at the same time. We’d be pretty much okay doing French & English together, but French & Norwegian started to get a little trying, and Italian & Greek couldn’t really be together at all.
We were very fortunate to be using Sun workstations in the editorial office. These were quite powerful Unix machines, which means that they were a fraction of the speed and capabilities of a Raspberry Pi. Suns had one particularly neat feature:
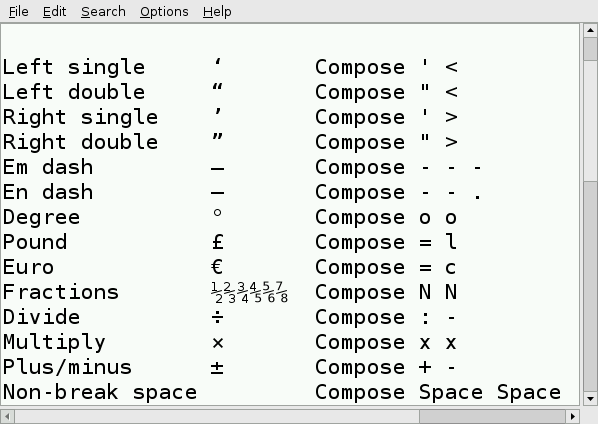
That little key marked “Compose” (to the right of the space bar) acted as a semi-smart typewriter backspace key: if you hit Compose, then the right key combination, an accented character or symbol would appear. Some of the straightforward compose key sequences are:
Like every (non-embedded) Linux system I’ve used, the Raspberry Pi running Raspbian can use the compose key method for entering extra characters. I’m annoyed, though, that almost every setup tutorial either says to disable it, or doesn’t explain what it’s for. Let me fix that for you …
Setup
Run raspi-config
sudo raspi-config
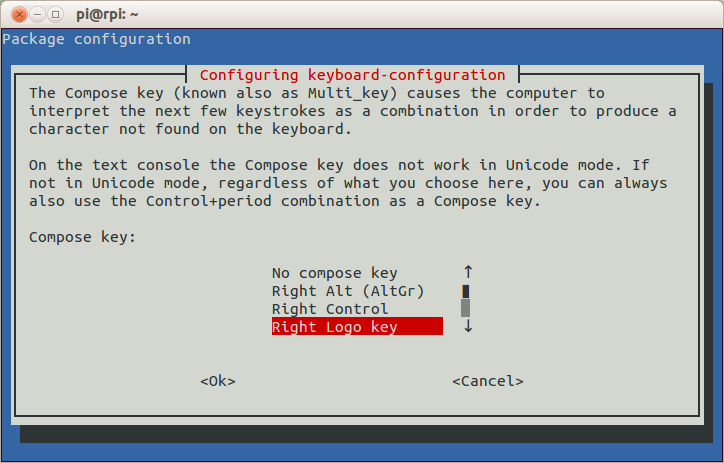
and go to the configure_keyboard “4 Internationalisation Options” → “I3 Change Keyboard Layout” section. Your keyboard’s probably mostly set up the way you want it, so hit the Tab key and select <Ok> until you get to the Compose key section:
Choose whatever is convenient. The combined keyboard and trackpad I use (a SolidTek KB-3910) with my Raspberry Pi has a couple of “Windows® Logo” keys, and the one on the right works for me. Keep the rest of the keyboard options the same, and exit raspi-config. After the message
Reloading keymap. This may take a short while
[ ok ] Setting preliminary keymap...done.
appears, you now have a working Compose key.
Using the Compose key
raspi-config hints (‘On the text console the Compose key does not work in Unicode mode …’) that Compose might not work everywhere with every piece of software. I’ve tested it across quite a few pieces of software — both on the text console and under LXDE — and support seems to be almost universal. The only differences I can find are:
Text Console — (a. k. a. the texty bit you see after booting) Despite raspi-config’s warning, accented alphabetical characters do seem to work (é è ñ ö ø å, etc). Most symbols, however, don’t (like ± × ÷ …). The currency symbol for your country is a special case. In Canada, I need to use Compose for € and £, but you’ve probably got a key for that.
LXDE — (a. k. a. the mousey bit you see after typing ‘startx’) All characters and symbols I’ve tried work everywhere, in LXTerminal, Leafpad, Midori, Dillo (browser), IDLE, and FocusWriter (a very minimal word processor).
Special characters in Python’s IDLESome Compose key sequences — Leafpad
To find out which key sequences do what, the Compose key – Wikipedia page is a decent start. I prefer the slightly friendlier Ubuntu references GtkComposeTable and Compose Key, or the almost unreadable but frighteningly comprehensive UTF-8 (Unicode) compose sequence reference (which is essentially mirrored on your Raspberry Pi as the file /usr/share/X11/locale/en_US.UTF-8/Compose). Now go forth and work that Compose key like a boß.