
Just some of the paper I made at the Introductory Papermaking Workshop at The Papertrail. It was a really excellent workshop.
work as if you live in the early days of a better nation
Just some of the paper I made at the Introductory Papermaking Workshop at The Papertrail. It was a really excellent workshop.

I’ve spent most of the day messing around with Twibright Optar, a way of creating printed archives of binary data that can be scanned back in and restored. It looks like it was written as a proof-of-concept, as the only way to change options is to modify the code and recompile. Eppur si muove.
To compile the code on OS X, I found I had to change this line in the Makefile from:
LDFLAGS=-lm
to
LDFLAGS=-lm `libpng-config --L_opts`
After trying to print some samples at the default resolution, I had no luck, so for reliability I halved the data density settings in the file optar.h:
#define XCROSSES 33 /* Number of crosses horizontally */ #define YCROSSES 43 /* Number of crosses vertically */
It’s quite important that your image prints and scans with a whole number of printer dots to image pixels. This used to be quite easy to do, before the advent of PDF’s “Scale to fit” misfeature, and also printer drivers that do a tonne of work in the background to “improve” the image. Add the mismatch between laser printer resolutions (300, 600, 1200 dpi …) and inkjets (360, 720, 1440 dpi …), and you’ve got lots of ways that this can go wrong.
Thankfully, there’s one common resolution that works across both types of printers. If you output the image at 120 dpi, that’s 5 laser printer dots at 600 dpi, or six inkjet dots at 720 dpi. And there was peace in the kingdom.
Here’s a demo, based on this:
So I took this track (which I used to have as a 7″, got at a jumble sale in the mid-70s) and converted it to a really low quality MPEG-2.5: MichelinJingle8kbit — that’s 175KB for just shy of three minutes of music (which, at this bitrate, sounds like it’s played through a layer of socks at the bottom of the Marianas Trench, but still).
Passing it through optar (which I wish wouldn’t produce PGM files; its output is mono) and bundling the pages into a PDF, I get this: optar_mj.pdf (760KB). Scanning that printout at 600dpi and running the pages through unoptar, I got this: optar1_mj.mp3. It’s the same as the input file, except padded with zeros at the end.
Sometimes, the scanning and conversion doesn’t do so well:
I’m on a major decluttering toot. When I realised that the filing cabinet I bought three years ago would no longer close with all the papers stuffed in it, I knew something had to change. I’ve been shredding like it’s Houston in 2001. I have the duplex scanner to suck in the stuff I need to keep. I’m moving to paperless wherever possible to stop it building up again.
My bank provides PDF statements. Of this I approve. PDF is almost perfect for this: it provides an electronic version of the page, but with searchable text and the potential for some level of security. Except, this is not the way that my bank does it. At first glance, the text looks pretty harmless:

Zoom in, and it gets a bit blocky:

Zoom right in:

Aargh! Blockarama! Did they really store text as bitmaps? Sure enough, pdftotext output from the files contains no text. Running pdfimages produces hundreds of tiny images; here’s just a few:
![]()
![]()
![]()
![]()
![]()
![]()
Dear oh dear. This format is the worst of electronic, combined with paper’s lack of computer indexability. The producer claims to be Xenos D2eVision. Smooth work there, Xenos.
So, how can I fix this? It’s a bit of a pain to set this workflow up, but what I’ve done is:
gs -SDEVICE=tiffg4 -r300x300 -sOutputFile=file%03d.tif -dNOPAUSE -dBATCH -- file.pdffor f in file*tif
do
tesseract $f `basename $f` hocr
donefor f in file*tif
do
cuneiform -f hocr -o `basename $f .tif`.html $f
donepdfbeads * > ../Output.pdfThe files are really small, and the text is recognized pretty well. It still looks pretty bad:
 but at least the text can be copied and indexed.
but at least the text can be copied and indexed.
This thread “Convert Scanned Images to a Single PDF File†got me up and running with PDFBeads. You might also have success using the method described here: “How to extract text with OCR from a PDF on Linux?†— it uses hocr2pdf to create single-page OCR’d PDFs, then joins them.
I wish the Toronto Star would stop giving me their Saturday edition. I already get the newspaper, so the Star is recycled unread every week. If it wasn’t 50% car section, I might take a glance.
Oh dear, tee hee: The Way of The Tosser.
A guy in our office washroom used NINE paper towels to dry his hands today. Two is maybe okay; you can make do with one.
The PhotoSmart has an ability to print various ruled paper forms: lined, todo lists, and graph paper. But what they print for graph paper is merely squared paper:

Graph paper’s the stuff with 1mm squares. Personally, I was disappointed that it wouldn’t print log ruled and Smith charts, but that’s just me …

This corner of Bloor & Bedford is about to be gone:

It has memories for us, as the first place we stayed when we arrived was just up the road. Breakfast was at Country Style (which became a Booster Juice after the massive Tim’s opened across the road), lunch was from Pita Factory, the daily paper from Gus at the Mac’s, dinner was sometimes at Swiss Chalet #1; all on the same block, all going to be gone.
If you look at the bigger picture, you’ll see that hugin neatly severed a couple of heads. It might smart a little, but with some bactine and gauze, it’ll grow back in the morning.
I was busy making Möbius strips out of till roll, when I became aware of a little face watching me at the window. A very damp raccoon had one paw up on the window sill, and was looking at me as if to ask, “What are you doing making single-sided paper figures on a night like this?”
The only downside about being part of the Billboard Battalion is that you get a lot of mail from the city. I get a separate letter for each variance contested, and sometimes duplicates, so I get between four and twelve letters after each community council meeting.
You would have thought they could have stuck them all in one envelope, or used e-mail, to save money and paper. But no; we’re a world class city, after all.
I’m not sure what to make of EWB‘s current campaign, which features a future newspaper headline G8 Leaders Declare End of Extreme Poverty. It links to playyourpart.ca, which seems to say that we can end world poverty just by buying fair-trade goods?
I know there’s a lot wrong with the coffee industry (Free Trade Coffee: You Grind The Beans, We Grind The Peasants! Enjoy the smooth trickle-down flavour, etc) but it’s a simplistic argument. What can the extremely poor sell to us?
I don’t know what to think.

The presenter of this paper claimed that PowerPoint changed α, the wind shear coefficient, to ✂. We laughed, briefly.
In the humour section at Chapters: George W Bush & his Family Paper Dolls book…
I love the HP LaserJet 4+. Built like a tank, good print quality, and now available used/refurb for pennies. Sure, they weight about as much as a Sherman, and suck power like there was no tomorrow, but one of my 4+s has nearly a million on the page count, yet prints crisp and clean.
Last weekend I scored a 4+ with built in duplexer from eBay for very little. It didn’t want to print at first (giving a cryptic 13 PAPER JAM error), but removing the rather beat-up full-ream paper tray fixed that. It may need a new cartridge (at almost twice what I paid for the printer), but I’m happy.
Wonder if I can direct-connect one of them to the ethernet port on Catherine’s eMac? I know my router won’t talk AppleTalk, so we can’t network just one printer.
I’d been suffering from some winter eczema on the blade of my right hand. It meant (like, if I wanted to) I couldn’t karate chop, but I could probably give someone a pretty good karate sandpapering.
It got worse recently, and beyond the control of over-the-counter meds. The doctor gave me a wee pottie of Elocom, a fearsome skin ointment, on Friday. The eczema’s almost gone; it’s just a tiny bit of dry skin now.
Just did my citizenship test. 20 questions, two of which you must get right, three of which you must get at least one right, and fifteen non-mandatory questions. Pass mark is 12/20.
Seemed not very difficult, either:— who was the first prime minister, who can vote, when was the Charter introduced, when did Newfoundland & Labrador join the Confederacy, when did Nunavut become a territory; that sort of thing. To think I spent all that time worrying about natural resources, the third line of O Canada! and Lieutenant Governors (sings: Bartleman, Bartleman, Does everything a … hey, wait a minute, just what can a bartle do, anyway?).
It did dismay and astonish me how badly prepared some people were. About 5 out of the 40 people didn’t turn up, and maybe 10 people didn’t have the requisite papers. C’mon people, don’t you want to be Canadian?
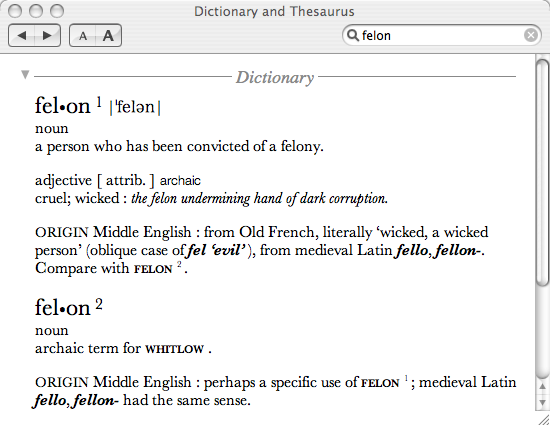
I was pleased to see that Apple had included a comprehensive dictionary with OS X 10.4. The Oxford American is a decent enough reference tome, and the computer implementation isn’t bad at all.
The typography’s fairly clean, if rather heavy on the whitespace. Cross references are active; if one clicks on the small-caps word whitlow, you’ll go to its definition (if you have to; it’s kinda nasty). For some reason, the Dashboard version of the dictionary doesn’t have active xrefs.
Searching isn’t as good as it could be. As with most electronic products, it assumes you already know how to spell the word. The incremental search does allow that, as long as you have the first few letters right, the list of possible choices is quite small. Like all electronic dictionaries that I’ve seen, it’s not possible to browse the text in that spectacularly non-linear way that makes a real paper dictionary fun.
It does seem to have a good few Canadian terms, but a true Canadian dictionary should be shipped with Canadian Tiger. Correct spelling isn’t just optional. It also only labels British and Canadian spellings as ‘British’.
So, in summary, pretty good, but far from perfect.