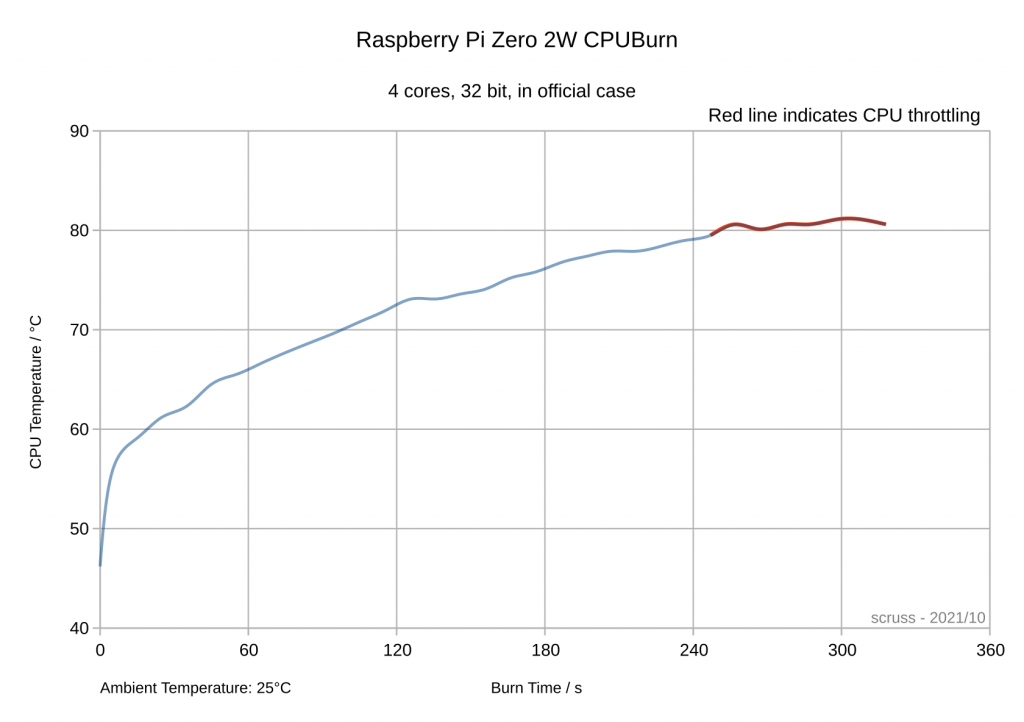
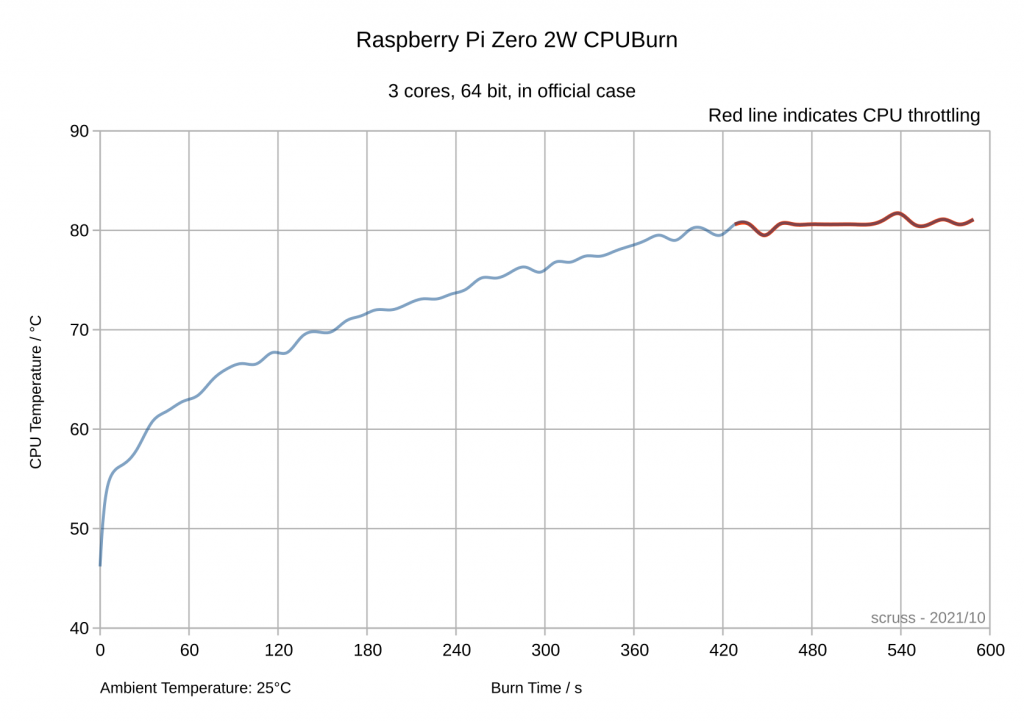
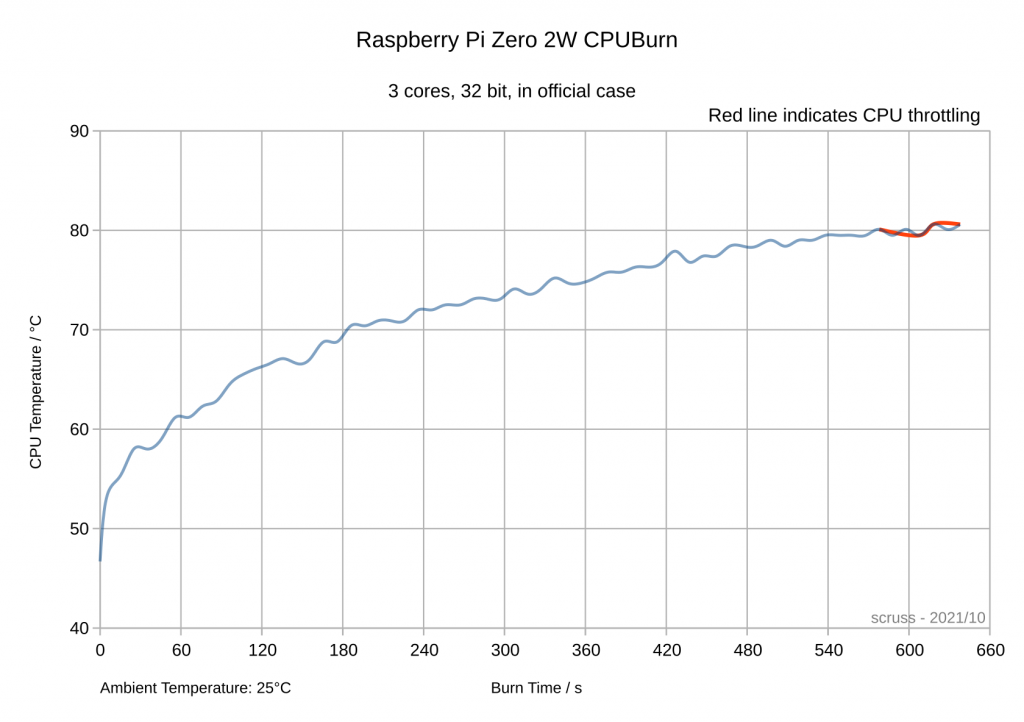
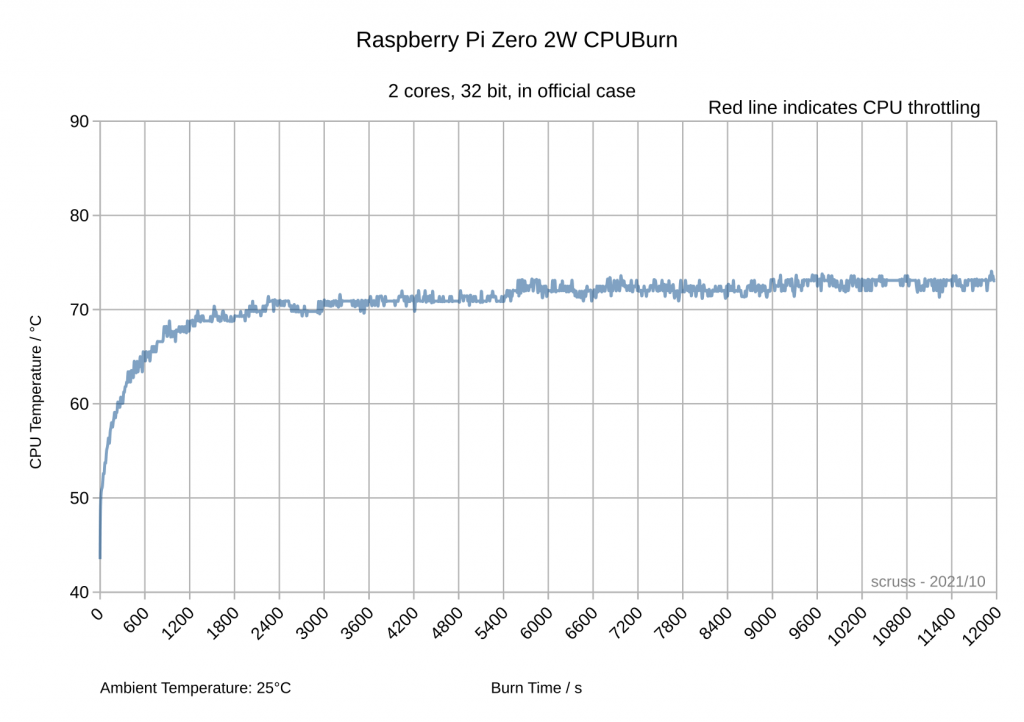
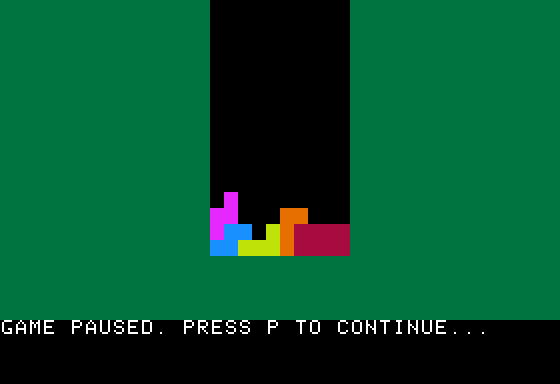Paleotronic want you to type it in, but life’s too short for that. You can play it in your browser on the Internet Archive: Tetris for Applesoft BASIC by Mark Stock
Life’s also too short for correcting OCR errors in BASIC code. Tesseract is hilariously bad at recognizing source code, so I had to go through this several times. AppleCommander’s BASIC Tools was very handy for catching the last of the errors with its variable dump: caught the cases of the TO keyword converted to the variable T0 … and frankly, I am no fan of SmartQuotes when applied to source code, either.
10 GOSUB 1000
100 W = W +1: IF W >LV THEN W = 0: GOSUB 350
110 K = PEEK(KB): IF K > = H THEN POKE KC,H:K = K -H: GOSUB 300
190 GOTO 100
200 PY = PY *A2: VLIN PY,PY +A1 AT PX: RETURN
225 PY = PY *A2: HLIN X1,X2 AT PY: HLIN X1,X2 AT PY +A1: RETURN
300 ON E(K) GOTO 30000,330,340,350,360,30100
310 RETURN
330 X = X -1: GOTO 400
340 X = X +1: GOTO 400
350 DN = 1:Y = Y +1: GOSUB 400:DN = 0: RETURN
360 S = S +1: IF S/4 = INT(S/4) THEN S = S -4
400 GOSUB 500
410 GOSUB 800: IF F = 0 THEN X = XX:Y = YY:S = SS: GOSUB 420: IF DN THEN GOSUB 900
420 COLOR= CF: FOR PP = 1 TO 4:PX = X +X(S,PP):PY = Y +Y(S,PP): GOSUB 200: NEXT PP:XX = X:YY = Y:SS = S:D = 0: RETURN
500 IF DD THEN RETURN
510 COLOR= CB: FOR PP = 1 TO 4:PX = XX +X(SS,PP):PY = YY +Y(SS,PP): GOSUB 200: NEXT PP:DD = 0: RETURN
800 F = 1: FOR PP = 1 TO 4:PY = Y +Y(SS,PP): ON ( FN PC(X +X(S,PP)) >0) GOTO 805: NEXT PP: RETURN
805 F = 0: RETURN
850 F = 1: RETURN
900 P = 10: GOSUB 30300
905 RN = 0:Y = YM
910 X = XL
920 PY = Y: IF FN PC(X) = CB THEN 950
930 X = X +1: IF X < = XR THEN 920
940 R(RN) = Y:RN = RN +1
950 Y = Y -1: IF Y > = 0 THEN 910
960 IF RN THEN GOSUB 30400
970 Y = 0
980 X = INT((XR -XL)/2) +XL
985 S = INT( RND(1) *NS):CF = C(S):S = S *4
990 GOSUB 800: IF F THEN RETURN
995 GOTO 31000
1000 DIM E(127),X(27,4),Y(27,4),R(40)
1010 TEXT : HOME : GR
1011 PRINT "WELCOME..."
1014 LM = 10
1015 XM = 10:YM = 15
1016 XL = INT((40 -XM)/2)
1017 XR = XL +XM -1
1021 A1 = 1
1022 A2 = 2
1030 DEF FN PC(X) = SCRN( X,PY *A2)
1040 CB = 0
1050 XX = 20:YY = 0:SS = 0
1100 KB = -16384
1110 KC = -16368
1120 H = 128
1129 REM KEYBOARD ACTIONS
1130 REM QUIT
1131 E( ASC("Q")) = 1
1132 E( ASC("Q") -64) = 1
1140 REM MOVE LEFT
1141 E(8) = 2
1142 E( ASC(",")) = 2
1150 REM MOVE RIGHT
1151 E(21) = 3
1152 E( ASC(".")) = 3
1160 REM MOVE DOWN
1161 E(32) = 4
1162 E( ASC("Z")) = 4
1170 REM ROTATE
1171 E( ASC("R")) = 5
1172 E(13) = 5
1173 E( ASC("A")) = 5
1179 REM PAUSE GAME
1180 E( ASC("P")) = 6
1181 E( ASC("P") -64) = 6
1185 GOSUB 2000
1186 GOSUB 1300
1190 PRINT "PRESS ANY KEY TO START..."
1191 PRINT
1192 PRINT "PRESS Q TO QUIT."
1193 GOTO 31020
1299 REM DRAW THE GAME
1300 COLOR= 4: FOR I = 0 TO 19:X1 = 0:X2 = 39:PY = I: GOSUB 225: NEXT
1320 COLOR= CB: FOR I = 0 TO YM:X1 = XL:X2 = XR:PY = I: GOSUB 225: NEXT
1350 RETURN
1400 DATA 1
1401 DATA 0,0,1,0,0,1,1,1
1402 DATA 0,0,1,0,0,1,1,1
1403 DATA 0,0,1,0,0,1,1,1
1404 DATA 0,0,1,0,0,1,1,1
1410 DATA 2
1411 DATA 0,1,1,1,2,1,3,1
1412 DATA 1,0,1,1,1,2,1,3
1413 DATA 0,1,1,1,2,1,3,1
1414 DATA 1,0,1,1,1,2,1,3
1420 DATA 12
1421 DATA 1,1,0,1,1,0,2,1
1422 DATA 1,1,0,1,1,0,1,2
1423 DATA 1,1,0,1,2,1,1,2
1424 DATA 1,1,1,0,2,1,1,2
1430 DATA 13
1431 DATA 1,1,0,1,2,1,0,2
1432 DATA 1,1,1,0,1,2,2,2
1433 DATA 1,1,0,1,2,1,2,0
1434 DATA 1,1,1,0,1,2,0,0
1440 DATA 9
1441 DATA 1,1,0,1,2,1,2,2
1442 DATA 1,1,1,0,1,2,2,0
1443 DATA 1,1,0,1,2,1,0,0
1444 DATA 1,1,1,0,1,2,0,2
1450 DATA 3
1451 DATA 1,1,1,0,0,0,2,1
1452 DATA 1,1,1,0,0,1,0,2
1453 DATA 1,1,1,0,0,0,2,1
1454 DATA 1,1,1,0,0,1,0,2
1460 DATA 6
1461 DATA 1,1,0,1,1,0,2,0
1462 DATA 1,1,0,1,0,0,1,2
1463 DATA 1,1,0,1,1,0,2,0
1464 DATA 1,1,0,1,0,0,1,2
1990 DATA -1
2000 X = 0:Y = 0
2010 NS = 0
2020 READ C: IF C < > -1 THEN C(NS) = C: FOR J = 0 TO 3: FOR I = 1 TO 4: READ X(NS *4 +J,I): READ Y(NS *4 +J,I): NEXT I: NEXT J:NS = NS +1: GOTO 2020
2030 RETURN
21210 P = 1: RETURN
30000 TEXT : HOME : END
30100 HOME
30110 PRINT "GAME PAUSED. PRESS P TO CONTINUE..."
30120 P = 1
30130 K = PEEK(KB): IF K > = H THEN POKE KC,H:K = K -H: GOSUB 30200
30140 IF P THEN 30130
30150 HOME
30160 PRINT "SCORE ";SC; TAB( 21);"LEVEL ";LM -LV +1
30170 RETURN
30200 ON E(K) GOTO 30000,30210,30210,30210,30210,30220
30210 RETURN
30220 P = 0
30230 RETURN
30300 SC = SC +P
30310 VTAB 21: HTAB 7
30320 PRINT SC;
30330 RETURN
30400 RN = RN -1
30410 FOR C = 0 TO 32
30415 COLOR= C
30420 FOR I = 0 TO RN:X1 = XL:X2 = XR:PY = R(I): GOSUB 225: NEXT I
30430 FOR I = 0 TO 2: NEXT I
30440 NEXT C
30450 FOR I = 0 TO RN
30460 Y = R(I) +I
30470 YP = Y -1: FOR X = XL TO XR:PY = YP: COLOR= FN PC(X):PX = X:PY = Y: GOSUB 200: NEXT X:Y = Y -1: IF Y >0 THEN 30470
30480 P = 100: GOSUB 30300
30490 NEXT I
30495 RETURN
31000 VTAB 22: PRINT
31010 PRINT " GAME OVER"
31020 P = 1
31030 K = PEEK(KB): IF K > = H THEN POKE KC,H:K = K -H: GOSUB 31200
31040 IF P THEN 31030
31050 D = 1
31060 SC = 0:LV = LM
31070 GOSUB 30150
31080 GOSUB 1300
31090 GOTO 905
31200 ON E(K) GOTO 30000
31210 P = 0: RETURN
32000 REM END OF LISTING